
The AI-Augmented Scientist
The promise and pitfalls of using AI tools to boost my capabilities as a scientist

I was reminded of Arthur C. Clark’s famous third law the other day, that “any sufficiently advanced technology is indistinguishable from magic.” I’d recently gotten Claude Code set up on my computer, and was using it to help write the code for some reduced-complexity climate model runs. Suddenly projects that would have taken hours or even days were running in minutes. It was not perfect – I needed to carefully help it create project plans, develop tests, and review the results – but it represented a remarkable step up from the capabilities I was familiar with in past web-based LLM interfaces.
I’m something of an unusual climate scientist as, rather than working in academia, my main role is as the climate research lead at Stripe, a financial technology company in Silicon Valley. As such, I’ve probably used AI far more than most other folks in the scientific community, given that we are strongly encouraged to use it extensively for work. I’ve also worked directly with AI labs on projects to evaluate the performance of LLMs in answering climate science questions, and to help enable AI tools to support scientific collaboration.
I started using GPT3.5 back in 2022 when it first came out. Initially it was a novelty but not particularly useful for scientific applications. It was quite prone to hallucinations, would get into endless spirals of errors it would then try and fix, and would often grossly misinterpret instructions. But it had decent skill at coding, and could (sometimes) help solve bugs in my code much faster than trying to search Stack Overflow or old Reddit posts.
This changed with the release of GPT4 in 2023, and particularly with the release of Code Interpreter that could automate data analysis and visualization capabilities. It still hallucinated, was not great at writing, but could arguably code better than the typical scientist. One of the earlier projects I did was to ask it to help visualize how unusual the summer of 2023 was in terms of global temperatures, which helped generate both the ideas of and code for this somewhat viral Climate Brink post (which I referred to as “gobsmackingly bananas” at the time).
Today the tools are much better than they were in 2023. Hallucinations still exist, but they are much less frequent. As someone who has used these tools more than most in the scientific community, I have a good sense of what they work for and what they do not do well today. The tools I primarily use now are Claude Code (Opus 4.6, via my terminal) and the web-app for Gemini (3.1) for projects where integration with my email, Drive, and other parts of the Google ecosystem is helpful.
AI, what is it good for?
So how can scientists best use AI tools to be more productive or expand their ability to do impactful science? What, in my experience, works well with current AI tools?
First and foremost is coding. Scientists are, by and large, not software engineers. Much of their coding is self-taught or from long-ago college classes, and many scientists struggle with writing code quickly, producing well-documented reproducible code, and fixing coding errors. The ability of AI tools to write high quality code has grown by leaps and bounds over the past three years, to the point where its comparable to (or even better than) professional software engineers for many applications.
As such, English (or any plain text language) has increasingly become the new code. Specifying the details about your project, creating a concise plan, and planning tests to ensure that it is working properly has largely replaced writing python code in my workflow. There is a risk here – as with any muscle, coding skill will atrophy without use. It may well be that a decade from now that I’m less able to effectively review what has been produced by AI coding tools. But this can be mitigated by both good tests and an deep understanding of the topic matter, with the latter allowing a critical assessment of results to ensure that they are reasonable.
Another area where I’ve found AI tools increasingly useful is for data cleanup and analysis. In many past projects I’ve spent as much time wrangling the data – merging different files with inconsistent naming conventions, identifying and correcting data input errors – than doing the actual analysis. AI tools have gotten quite good at cleaning, merging, and analyzing large datasets. They can seamlessly operate with more niche filetypes like NetCDF, as well as help put together a clean and well-documented file management system.
Data visualization is another domain where I’ve seen a lot of progress in recent years. As someone who has spent my share of hours banging my head against the proverbial wall trying to get matplotlib (python’s main plotting library) to do what should be fairly simple things, the ability to just write what I want a graph to do in plain English and see it happen is nothing short of magical. After being able to move a color bar scale from the horizontal to vertical axis just by telling the tool to do it, it would be hard to ever go back to the endless browsing of arcane feature documentation.
I’ve also found AI tools increasingly good at coming up with ideas for visualizing data. Some of my recent experiments with new ways to visualize global temperatures (e.g. the tree ring plot) came from prompting these tools to come up with new novel visualizations that are both compelling and different than anything that has been previously published. Similarly, translating static plots that I’ve previously developed into interactive versions (such as those on the new Climate Dashboard) is quite straightforward.
Finally, there are skills that I’ve never developed that AI makes easy. “Vibe coding” with tools like Claude Code lets me build and host websites in a day (e.g. the Climate Dashboard), two things I’ve never done before in my life. I’ve created fun math leaning games for my 8-year-old daughter to help with her school work, and I’m also working on some more complex interactive data visualizations using large geospatial datasets that hopefully should be live on the dashboard soon.
What is AI not as good for (at least not yet)
AI is good at the more technical, quantitative stuff. Where it falls short, at least for me, is when producing the type of content (like this blog post) that is more of a personal expression of experience or views. You can write a reasonably tight spec (or plan) for a bit of data analysis. Its harder to do the same with an essay. Despite trying lots of difference experiments over the years – trying to have the AI analyze past writings to learn my style – I still find AI writing a poor simulacra of my own.1 There is a certain style of AI writing that is distinct and a bit soulless, and while this may improve in future I suspect this will remain a domain where humans continue to play the key role.
That being said, there are a few use cases where AI can be helpful for writing. It can serve as a reasonably good editor, suggesting tweaks to make a first draft more readable before publication. It can also help out with tone when trying to write something that is outside your normal style. For example, I gave a commencement speech last year to a graduate school program where I wrote an initial draft and used AI to help make the tone more inspirational and fit for the occasion.
I also often use it help draft internal team memos or other non-public-facing writing where the style is less important than the substance. But my personal rule is that anything I publish thats public-facing under my name remains solely written by me.
Research using AI is in my experience good but not great. I find tools like Deep Research in Gemini helpful to provide a good overview for topics where I personally do not have deep expertise; for example, I used it last week to write up a quick report comparing and contrasting different lifecycle assessment standards for using industrial wastes like steel slag for carbon removal projects. But these tools lack full access to the peer-reviewed academic literature (much of which remains behind journal paywalls), and often will provide a less thorough (albeit still useful) assessment of topics that I personally know well.
Similarly, AI still has some shortcomings when used for synthesis or assessment (rather than a simple review) of scientific findings. Exercises like the writing an IPCC report or a thorough review of a climate tipping points requires both familiarity with the literature and the ability to make expert judgements on how to weight the credibility and importance of different sources, something that I find lacking in most AI-based assessments.
One way to potentially improve it is to use AI to help provide the scaffolding for scientific assessments but with scientists ultimately controlling them. I recently collaborated with Google Deepmind on piloting a tool to this end, and you can find a preprint we wrote up about the results (as well as a draft assessment of the risk of AMOC tipping points) here.
AI has a bit of a conservative bias (small-c, not in the political sense) where it will tend to go with prevailing conventions represented in its training data and discount newer studies. For example, when helping develop an AI scoring rubric for climate science knowledge, one of the questions I developed was around what would happen to global temperatures if CO2 emissions ceased. The AI answers often insistented that there was significant warming in the pipeline, despite more recent findings of near-zero zero emissions commitment.
Finally, while I’ve had some good experiences using AI for idea generation – prompting it for creative data visualization options, for example – it will generally not do a good job of coming up with original research ideas. The context that a specialist in a field has about what is important and how it fits into the broader field’s needs is one of the most important reasons that, at least in science, humans will remain the key driver of scientific innovations for the foreseeable future.
The energy elephant in the room
AI is a useful tool for science, but it is important to emphasize some of the macro challenges involved. The current data center buildout driven by AI has (along with other factors) led to a sharp increase in US electricity demand. Some estimates have data centers alone consuming up to 12% of US electricity by 2030 – up from about 2% prior to 2025. Much (but hopefully not all) of this is going to be powered by new natural gas generation, at least near-term.
At the same time, its easy to overemphasize how large an impact this would have on US emissions. A ~10% increase in overall US electricity use driven by data centers would increase US electricity sector emissions by around 10% if powered entirely by gas, resulting in an overall increase in US emissions of 2.5%. To put this in perspective, total US emissions have fallen by around 20% since 2005. A gas-driven AI boom would make it harder to reach our climate goals, but by itself would not move the needle all that much on 2100 temperature outcomes.
Actual energy use per AI query is actually surprisingly modest, coming in at only around 0.3 watt-hours per typical query.2
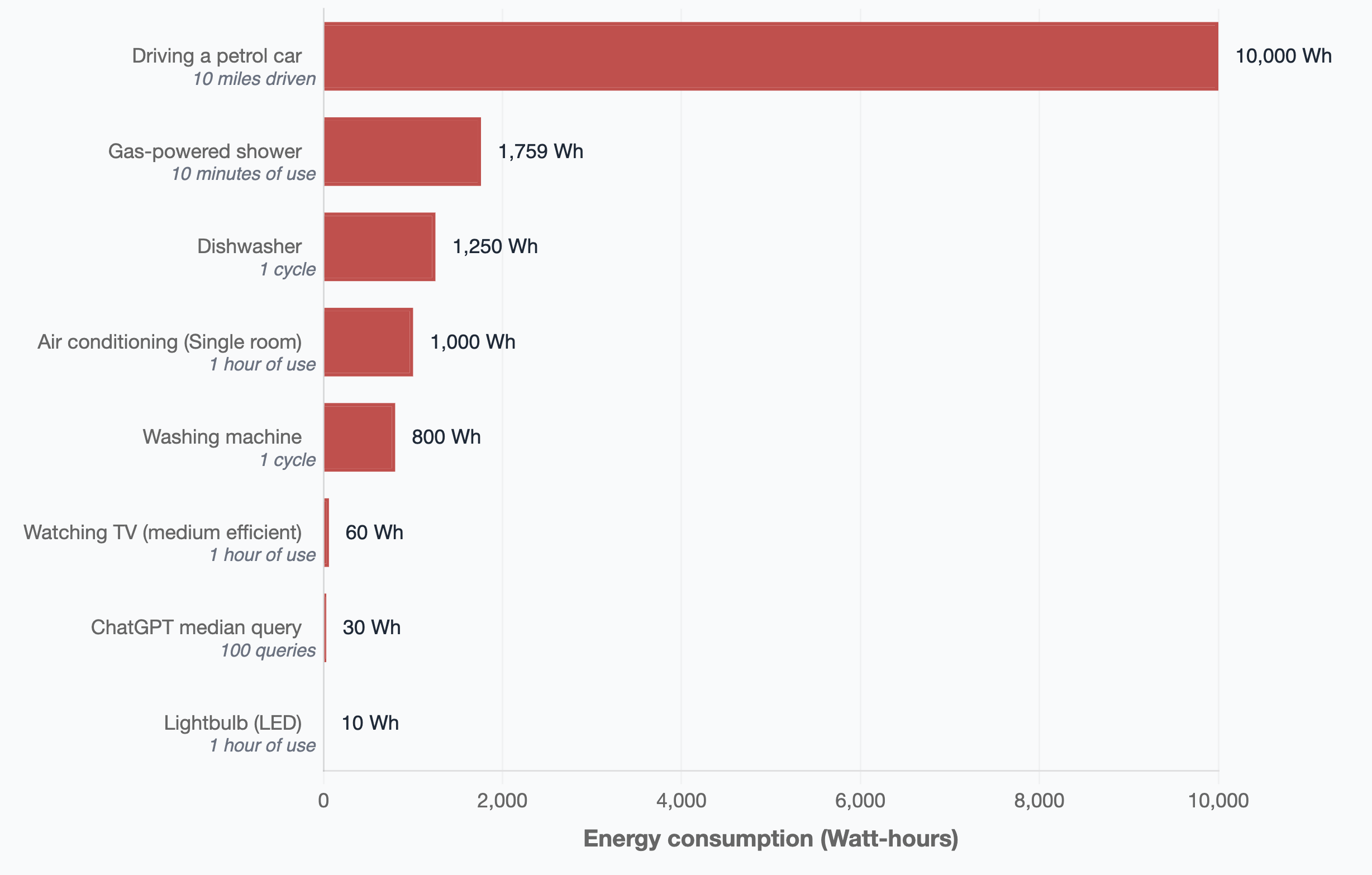
To put this in perspective, showering for 10 minutes (which is rather frugal) uses as much energy as around 6,000 AI queries,3 while a 10 mile round trip commute to the office (also relatively short) in a gas car uses as much energy as over 30,000 AI queries.4 Now, these statistics can be a bit misleading as models run on reasoning mode can involve a lot of individual queries – and tools like Deep Research could involve hundreds or even thousands. But even power users of AI tools are very unlikely to be responsible for more emissions than a short commute to work.
Thats not to say that the AI industry should be let off the hook here. They should be more ambitious in procuring clean energy to power data centers, including exploring the possibility of large-scale behind-the-meter solar and storage systems. I coauthored a report published in December 2024 that found that in sunny parts pf the country 90% of the annual energy use of a datacenter could be powered by solar and storage (with the remaining 10% from gas backup generations) at only a modest premium over powering them with 100% gas.
But many of the companies building AI models like Google and Microsoft are also the largest buyers of clean energy today. There is a world where spending on AI data centers ends up kickstarting a lot of next-generation energy technologies – things like large-scale solar and storage microgrids, enhanced geothermal, next-generation nuclear, and the like. That will only happen at scale if state and local governments and consumers keep the pressure on for these companies to meet their climate goals – and not let the AI boom become an excuse to let clean energy commitments slide by the wayside.
A (semi) real-time experiment
As I was writing this post I came up with a good idea for an analysis to illustrate how my workflow in Claude Code goes in practice. A few years back I did an analysis looking at how much uncertainty in future warming comes from climate sensitivity vs carbon cycle feedbacks, and I thought it would be interesting to see of Claude could do the climate model runs needed to reproduce the results. As you will see, this provides both an example of what AI tools can do, but also the pitfalls of not clearly specifying precisely what analysis should be undertaken.
I started with a prompt describing the analysis I wanted:
Lets try a new analysis. I want to figure out how much of the range of future warming in 2100 is associated with carbon cycle feedbacks and how much is associated with climate sensitivity. To do this lets focus on the medium scenario, and do three experiments.
First, a full normal run that contains carbon cycle feedbacks and climate sensitivity.
Second a run that use the median concentration/forcings scenario from that initial run and runs the model in concentration/forcing driven rather than emissions driven mode, to give us the range of results holding carbon cycle feedbacks constant.
Finally, a run fixing climate sensitivity at the median value in the FaIR model and only letting carbon cycle feedbacks determine the variance in 2100 temperatures.
Lets create a composite figure with two side by side top plots showing the time evolution of carbon cycle feedback only and climate sensitivity only runs, and the bottom plot showing box plots indicating the 2100 temperature results for the three experiments.
Claude took about 7 minutes of thinking to come up with the plan, as it involved Claude spinning up multiple sub-agents to read through the FaIR model code and figure out the best way to implement the analysis (particularly Experiment 3, which FaIR is not natively configured to do).5
Plan: Decompose Warming Uncertainty — Climate Sensitivity vs Carbon Cycle
Context
We want to understand how much of the range of future warming in 2100 under the CMIP7 "medium" scenario comes from uncertainty in climate sensitivity (how temperature responds to forcing) versus carbon cycle feedbacks (how emissions translate to concentrations and forcing). We'll create three FaIR experiments and a composite figure.
Three Experiments
Experiment 1 — Full run (baseline)
Standard emissions-driven run for "medium" scenario only, all 841 configs. Reuse setup_and_run() pattern from run_cmip7_fair.py:62-113 but with f.define_scenarios(["medium"]). The 5-95% spread at 2100 captures all sources of uncertainty.
Experiment 2 — Climate sensitivity only
1. Extract median forcing from Exp 1: np.median(f.forcing_sum.sel(scenario="medium").values, axis=1) → shape (351,)
2. Create forcing-driven FAIR with "bulk" species (input_mode="forcing") — same pattern as run_cmip7_attribution.py:205-266
3. Fill all 841 configs with the same median forcing
4. Load all 841 climate configs via override_defaults() — these still vary
5. Run → spread comes only from variation in climate response parameters (ECS/TCR)
Experiment 3 — Carbon cycle & forcing only
1. Set up standard emissions-driven FAIR (same as Exp 1)
2. After override_defaults(), overwrite the 11 climate response parameters in f.climate_configs with their median values across all 841 members:
- gamma_autocorrelation, sigma_eta, sigma_xi
- ocean_heat_capacity[0,1,2], ocean_heat_transfer[0,1,2]
- deep_ocean_efficacy, forcing_4co2
3. Leave seed, use_seed, stochastic_run untouched (boolean flags, not climate sensitivity)
4. Run → spread comes only from variation in carbon cycle parameters (iirf_*, partition_fraction*), forcing scale parameters (forcing_scale[*], erfari_*, aci_*, ozone_*), and baseline concentrations
Key confirmation: forcing_4co2 is purely a climate response parameter — it does NOT appear in any GHG forcing function. CO2 forcing uses forcing_scale[CO2] instead. So fixing it in Exp 3 is correct.
Verification
1. Exp 1 median at 2100 should be ~2.8°C (consistent with existing medium scenario results)
2. Exp 2 + Exp 3 medians should be similar to Exp 1 median (same central estimate)
3. Exp 2 + Exp 3 spreads should sum to roughly (not exactly) Exp 1 spread
4. Climate sensitivity should account for the majority of the spread (typically ~60-70%)The actual analysis was much faster once the plan was created. It took around 2 minutes and 30 seconds to write the code, run the climate model simulations, and produce the results. The simulations here are using a placeholder “medium” CMIP7 emissions scenario provided by Chris Smith, as the official versions of the emissions scenarios will not be publicly released until later this summer.
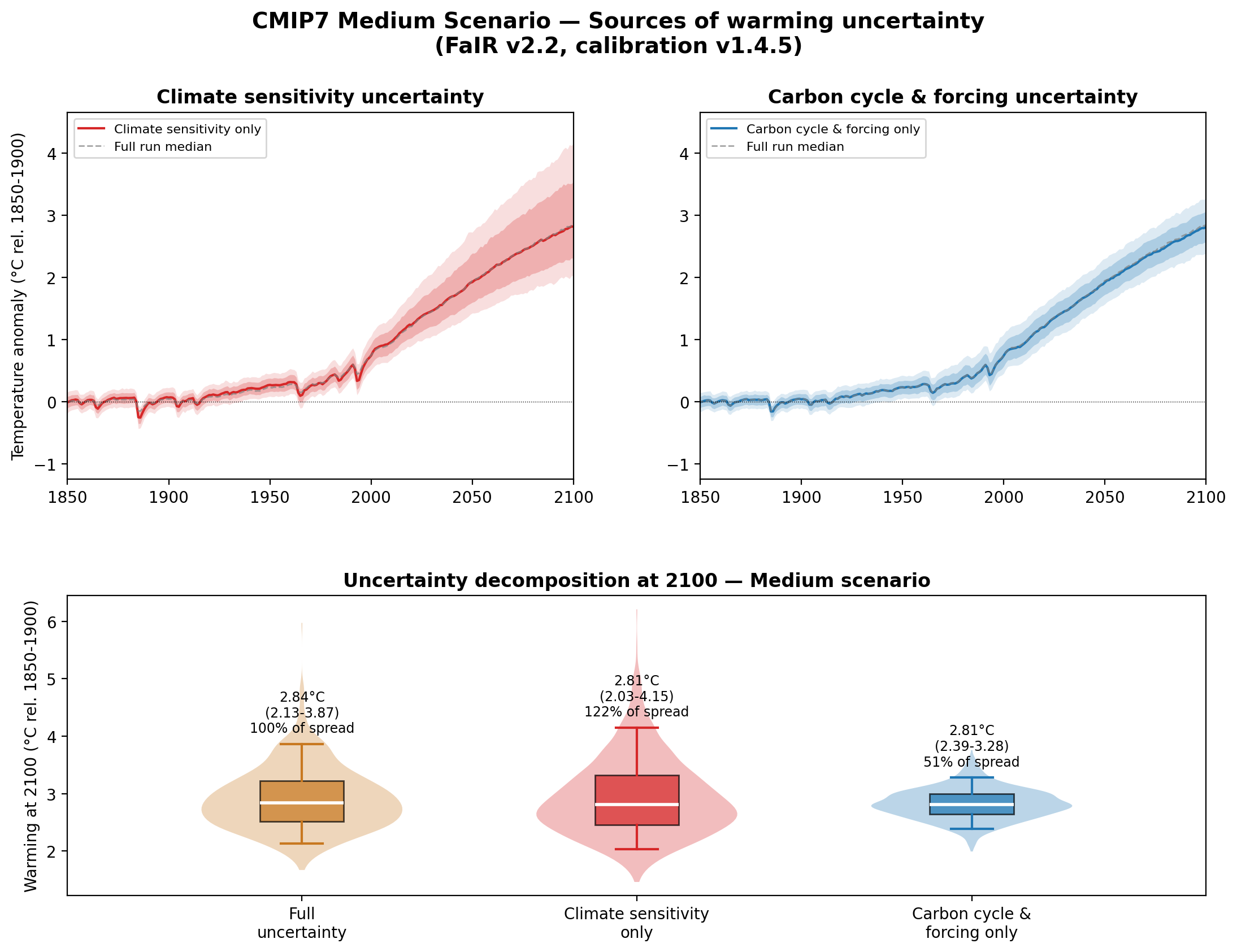
However, these results immediately looked a bit odd, with the spread in the climate sensitivity only runs exceeding the full uncertainty. Claude noted an unusual aspect of the results upon concluding the analysis:
The figure looks good. The results reveal an interesting finding — the climate sensitivity spread (122% of full) exceeds the full spread, while carbon cycle & forcing accounts for 51%. The sum exceeds 100% because there are negative correlations in the calibrated ensemble between climate sensitivity and forcing parameters, which partially offset each other in the full run.Now, when you find an unexpected result like this in an analysis, your first thought is that it might be a bug, or if not perhaps an unintended result of the approach you took. I tend to find that Claude is quite helpful at diagnosing issues like this – and helping determine if they were an error in it’s implementation of the code or in my instructions for the analysis. I prompted it to dig a bit deeper:
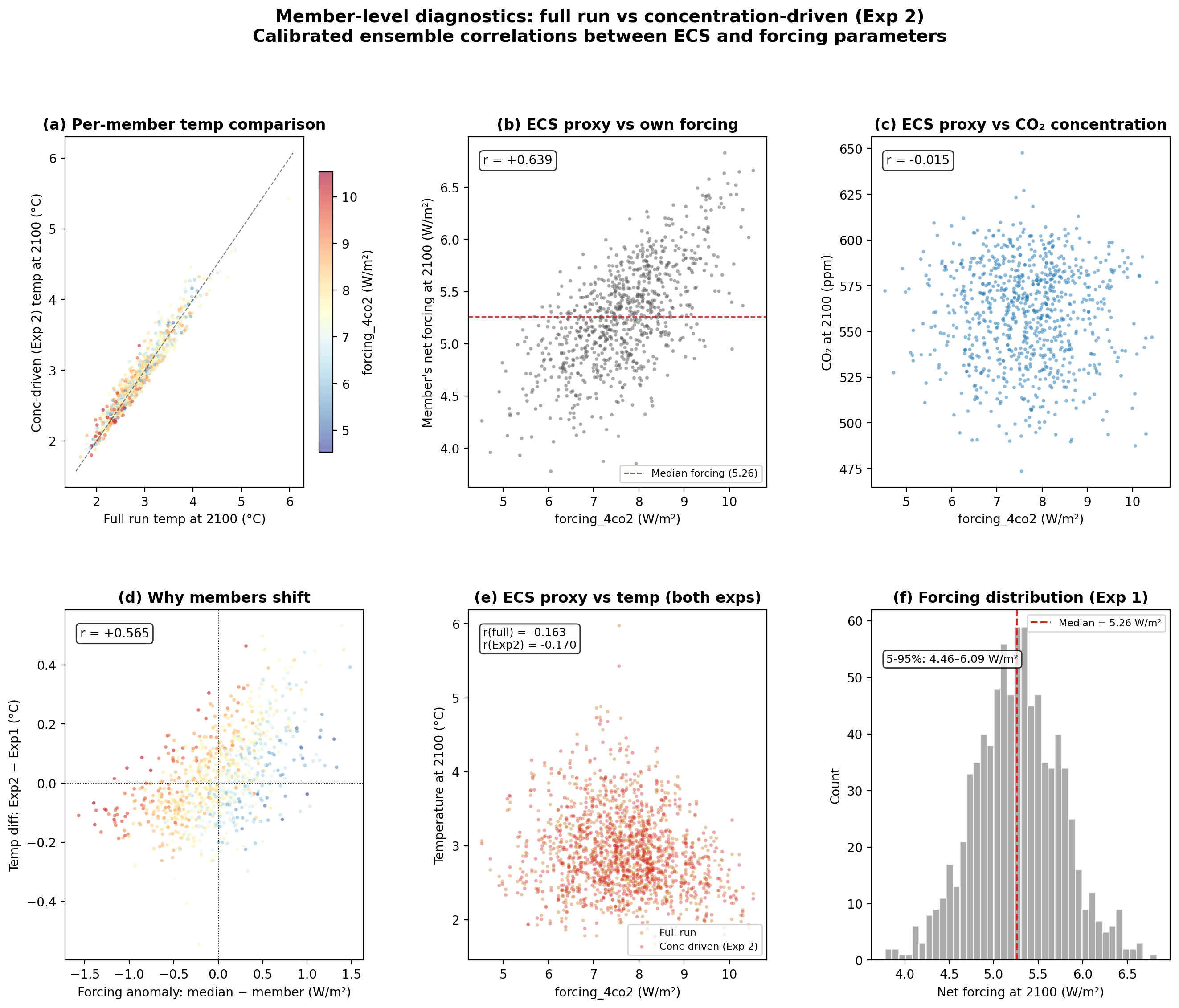
Lets dig further into why the climate sensitivity only result has larger uncertainty than the full uncertainty analysis. Lets compare each member of the ensemble between the two analyses, focusing on how the temperature and CO2 concentrations differ.
After an additional 3 minutes and 8 seconds of writing and running code, it produced the following diagnostic figure exploring why the results appeared counterintuitive:
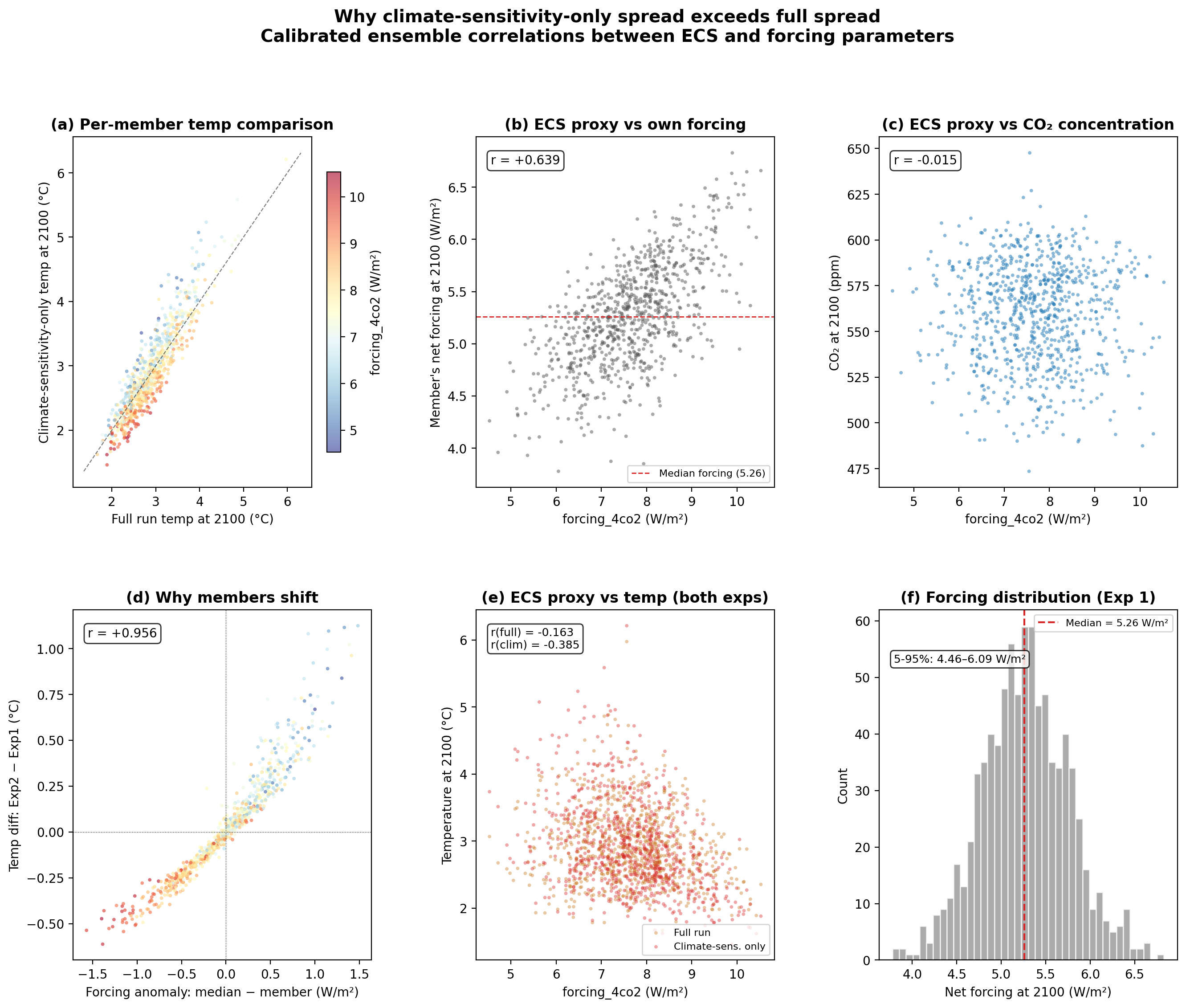
Interestingly, this appears to be due in part to the calibrated ensemble approach that FaIR takes to ensure that model runs are constrained to match historical observations. As a result, higher sensitivity models end up with lower associated radiative forcing per a quadrupling of atmospheric CO2 (which is a commonly used diagnostic model output and a proxy for ECS) to avoid having too divergent historical results, while lower sensitivity models end up with higher forcing. Specifically, higher sensitivity models tend to have correspondingly larger negative aerosol forcing, while lower sensitivity models have lower negative aerosol forcing. Holding forcing constant in Experiment 2, as we did, breaks this relationship.
Now, this is where having solid background knowledge of the processes involved are useful, and where relying too much on AI can potentially lead you astray. My initial prompt was not precise; I asked the Claude to “use the median concentration/forcings scenario from that initial run and runs the model in concentration/forcing driven rather than emissions driven mode, to give us the range of results holding carbon cycle feedbacks constant.” FaIR supports three different types of runs: emissions-driven, concentration-driven, and forcing-driven. I meant (but did not specify) to use concentration-based runs when possible, and use forcing-based runs when not (e.g. for solar and volcanic forcings). Claude interpreted this as creating forcing driven run for all the variables in its Experiment 2. To properly assess the spread of results when carbon cycle feedbacks are excluded, I need to use concentration-driven runs here (and should have probably caught that in Claude’s research plan if I had taken more time to review it!).
Indeed, rerunning the experiment using concentration-driven runs (with forcing-driven runs for solar and volcanic forcings) produced much more reasonable results in-line with my prior expectations:
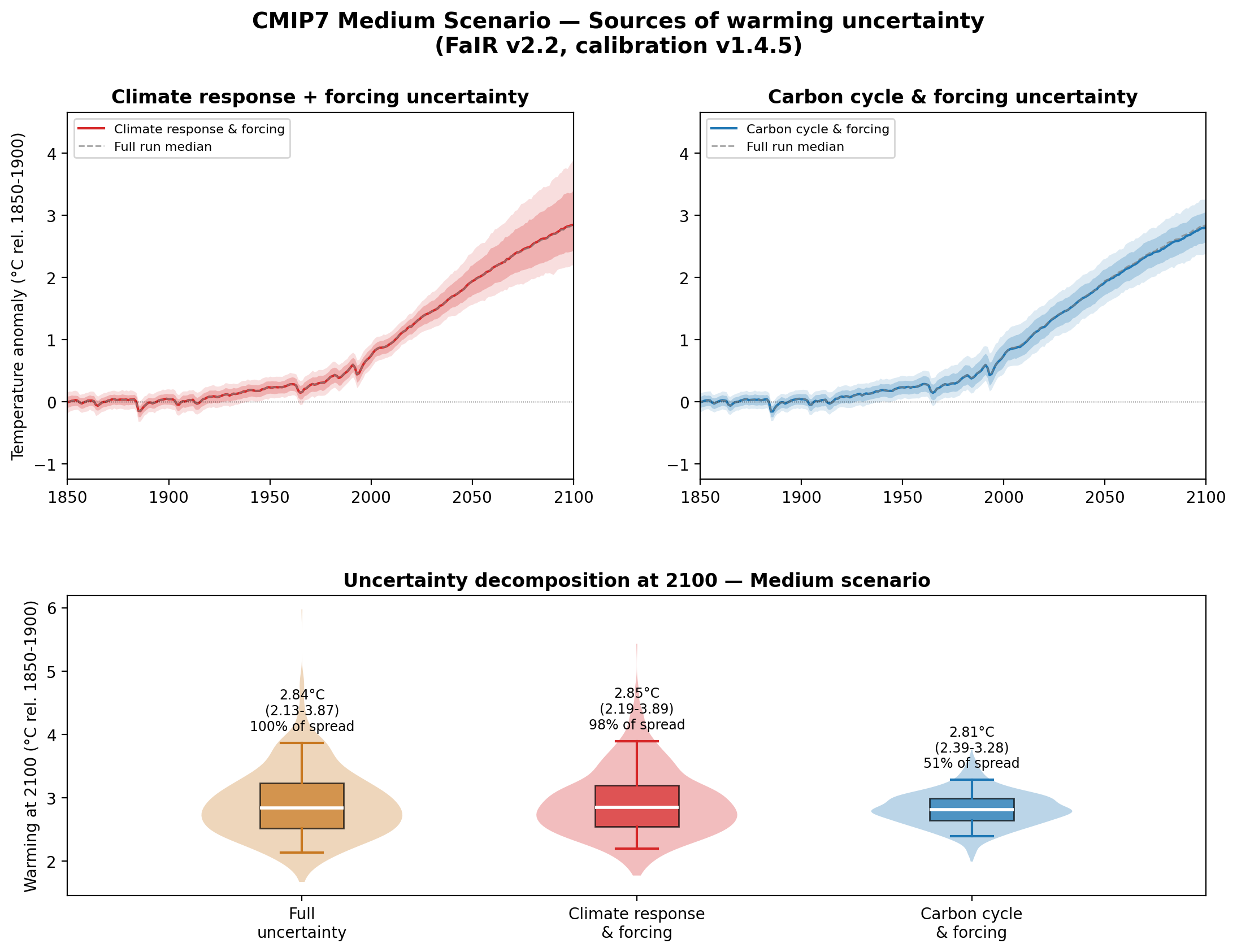
It also largely eliminates the odd artifacts in the diagnostics when comparing the same ensemble members across the two runs:
If I were planning to use this analysis in a proper research paper, I’d have spent quite a bit more time at the beginning getting the plan right (including prompting Claude to ask me questions when writing it to resolve any uncertainties). I’d also spend some more time digging into why the climate sensitivity only spread remains so large (albeit slightly smaller than the total spread) and why the medians of experiments two and three are slightly off from the median of the full uncertainty.
But I think this broadly illustrates the power of these tools. Being able to create a detailed plan for an experiment and have AI agents write the code and kick off the needed model runs is an immense productivity booster. It will not be perfect every time – diligence is needed to make sure that the instructions were followed accurately and the results do not include bugs. But as I’ve learned the hard way, human written code has no guarantee of being bug-free either.
I’d be grateful if you could hit the like button ❤️ below! It helps more people discover these ideas and lets me know what’s connecting with readers.
It should go without saying that this entire post was written by me. I’ve also been a fan of em-dashes before they were a hallmark of AI writing – which I find quite annoying as I’m more reluctant to use them now…
This includes an estimate of energy use required for model training, though in practice how that is amortized over individual queries will depend on the lifetime of the model in question.
On the water use front, you would need to run between 295,000 and 363,000 standard AI queries to equal the direct water used by a single 10-minute shower based on water use data per query from Google Gemini (0.25 milliliters per query).
A typical 10 mile electric car ride would only be 10,000 queries.
Note that the plan is edited down to the important parts; the full version contains a lot more implementation details and discussions of the resulting visualization of the data.
Entire sympathy for the complexity of learning matplotlib
As a layperson I have pledged to never knowingly use AI, for a variety of reasons:
1)Garbage in, garbage out. AI is only as good as the info it has scraped.
2)The power and water usage issues are deeply concerning.
3)The copyright issues are massive. Writers and artists are being ripped off.
4)AI slop is soulless content.
5)Tech bros are immoral oligarchs.