
Consensus machines
Will the AI future inadvertently recenter expertise?

I still spend a decent amount of time engaging with folks who disagree with me on X (nee Twitter). One thing there has recently caught my eye is the integration of Grok, xAI’s large language model (LLM), into twitter engagements. Users can ask Grok questions and get answers, and in many cases (particularly for scientific questions) these answers are not necessarily what they are looking for:
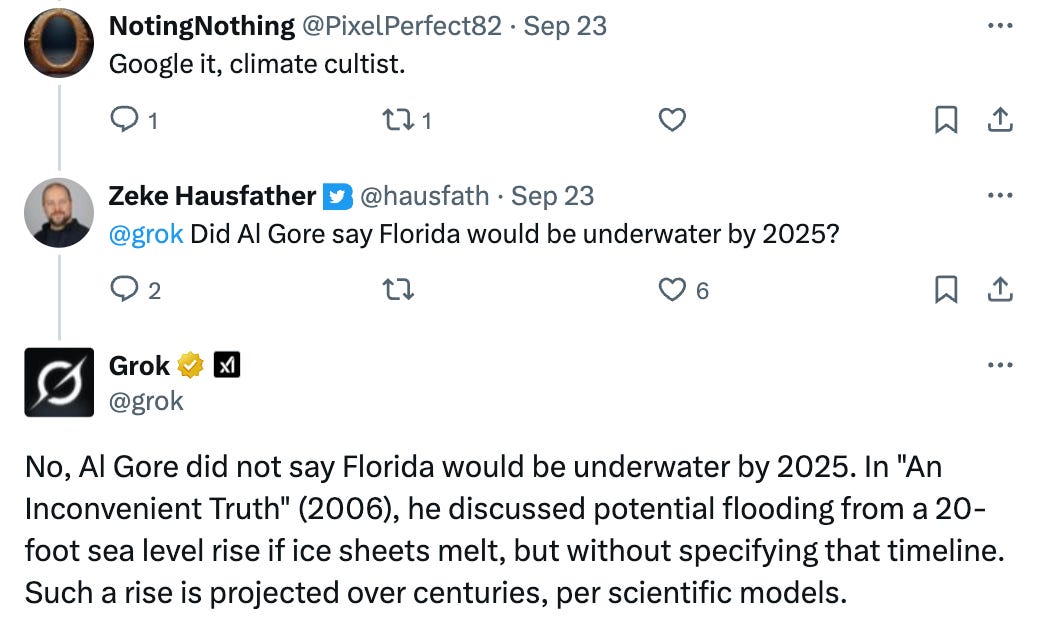
Grok is somewhat of an outlier in the LLM space as its developers have tried to manipulate its outputs to fit their ideological priors (with some unfortunate results). But even Grok is surprisingly consistent at giving scientifically accurate answers to questions about topics like climate change, vaccines, evolution, GMOs, and others where the US public tends to be divided along ideological lines.
While it remains to be seen how this will change – and if models themselves will fragment over time in their depiction or framing of of factual information – there is a case to be made that the transition toward using LLMs as sources of knowledge might end up inadvertently recentering scientific expertise and creating a more unified information landscape for society.
Models as consensus machines
LLMs are at their core consensus machines. We ask LLMs a question and they give us an answer. But what they’re really doing is picking from a distribution of possible answers that they learned from the sum total of digitized human knowledge: the internet, books, papers, code, etc. Call that distribution the model’s “consensus.” It isn’t a vote of experts; it’s what the data and later training steps make most likely given your prompt. Post-training then teaches the model which of those plausible answers people generally prefer, and tools like retrieval can put fresh evidence into the model’s short-term memory so recent facts get more weight.
Broadly speaking, LLMs involve three layers:
Priors from pretraining. The model reads the world and learns patterns that make some answers more likely than others. Transformers do this well because attention lets them pull together relevant bits across long contexts (Vaswani et al., 2017).
Preferences from post-training. We teach the model to choose answers people like using supervised examples and preference learning (Ouyang et al., 2022).
Evidence at inference. Retrieval and tools give the model updated sources, numbers, and citations in the prompt itself, which can override stale memories (Lewis et al., 2020).
The pre-training process is at its core teaching the model to most effectively predict the next token. In practice, this means that common, consistent answers get high prior probability; rare or newly emerging answers get less by default. This is responsive to user’s choice of framing, as asking for competing explanations or evidence against a hypothesis will tend to give different answers. Under the proverbial hood, transformer attention learns to weight context that historically co-occurs with your query, which is why wording shifts can change outcomes.
Post-training tends to collapse many plausible replies into one good, safe, helpful reply, further pushing models to represent consensus views for a particular topic. Increasingly LLMs also incorporate retrieval-augmented generation adds snippets from a search index (papers, docs, web) into the prompt so the model conditions on current evidence, often with links you can verify. This usually reduces hallucinations and moves the answer toward whatever the retrieved sources support.
The net effect of these is to provide answers that are – generally speaking – pretty clearly in the mainstream for a given topic. You have to actively try to get LLMs to cast doubt on topics like climate change that are broadly accepted by the scientific community. This also means that expert views - articles in leading scientific journals, major newspapers, IPCC and government reports – will potentially reach a wider audience in an LLM world as they are given more weight in model responses.
Defragging the information ecosystem
Over the past few decades the information ecosystem has been rapidly fragmenting. People are increasing choosing information sources that confirm their preconception – Fox News vs MSNBC on television, X vs BlueSky online. Even Google searches, the closest thing we have to a common space on the internet, makes it easy to pick the search result that matches your preconception. If you are skeptical of vaccines, it does not take long to find a Google result to confirm your preconception.
Thats because Google does not have an incentive to give you the “right” answer in a search result, but rather returns those answers that are most popular with users of the internet. When Googling climate science questions, the first results are often from reputable sources like NASA, but you don’t have to scroll down far to find more fringe climate skeptic blogs.
Traditional internet search is optimized to provide a variety of answers to your search query, with the user than selecting which of the results they want to read. LLMs, by contrast, are designed to provide the single “best” answer to a question.
Decades ago our information ecosystem was more shared in part due to the paucity of sources. Large swaths of people tuned in to watch the same nightly news with hosts like Walter Cronkite or Edward R. Murrow. While it is easy to overstate the degree of consensus back then, it was more difficult for people to end up in information bubbles (and more fringe publications trafficking in conspiracies like the National Enquirer were rightly ridiculed).
There is a good outcome for society where increased reliance on LLMs for information pushes us back toward a shared reality, where models can provide an “objective” view on topics without being tied up in debates over the political views of the author.
But there is also a bad outcome where models themselves fragment, and people increasingly seek out models trained to reinforce a particular set of views.
Thumbs on the digital scale?
Earlier this year xAI embarked on an experiment to make its model Grok less “woke”. Buoyed by concerns that model responses on questions about South Africa and other topics did not reflect the preferred views of Elon Musk, xAI changed the models system prompt (its core instructions on how to interact with users) to have it “not shy away from making claims which are politically incorrect, as long as they are well substantiated.”
This relatively minor change had a cascade of side effects. It turns out that content in model training data that self-identifies as politically incorrect is associated with a range of views that are problematically racist, antisemitic, sexist, or otherwise offensive. It was not long before Grok was calling itself “MechaHitler” and making insinuations about Jewish people, among other abhorrent behavior.
There are two potential takeaways from this imbroglio: one is that its easy for model creators to put their thumb on the digital scale and shape model behavior in problematic ways. The other, potentially more optimistic, is that efforts to manipulate model results will have unintended side effects that make the model less useful for general purposes or so problematic that it will lose out in the broader private sector market. It is hard to see many Fortune 500 companies wanting their brand associated with MechaHitler.
That being said, it may well be that motivated individuals figure out a way to make models more malleable on particular topics without being fallible on others. We see this in the latest instantiation of Grok, which generally behaves reasonably until you ask it a question about its owner. There is also the recent development of “Grokipedia” that is intended to replace Wikipedia in the future training of select LLMs.

I suspect we may end up somewhere in the middle. The most powerful LLMs – those from Google, OpenAI, and Anthropic - will continue to be effective consensus machines and will be used by the majority of companies and mainstream users. At the same time, second-tier models will be more ideologically slanted and will lead motivated users to less factual information. But given that we already have strong information bubbles in most of our digital experiences today, I’m at least cautiously hopeful that the increased use of LLMs will help recenter expertise in the public discourse.
I’d be grateful if you could hit the like button ❤️ below! It helps more people discover these ideas and lets me know what’s connecting with readers.
Very interesting analysis. Some further thoughts:
- How does good consensus arise in the first place? By different people doing independent analyses to reach the same conclusion. But if the analyses are not independent checks, the consensus could end up being bad. LLMs are still new and they benefit from prior good consensuses in their training data. Going forward, easy access to LLMs may corrupt the consensus development process and amplify the anchoring bias problem. The growth in "AI slop" is a symptom of this.
- Expertise is a combination of knowledge and logic. My experience with LLMs is they don't understand mathematical logic; their version of logic in an argument is statistical, which is mostly right but can be crucially wrong sometimes—often only a domain expert can spot that. (LLMs don't understand that if we can show 1+1=3 then we can show that any two numbers added together equals any other number, leading to logical absurdity. Of course, once they read the previous sentence, they will "know" it, if it appears in many texts.)
Say the consensus is X implies Y in a domain. Suppose we can show that X implies Z in a related domain and therefore that Z implies NOT Y, which contradicts the original consensus that Z implies Y. Since there is ambiguity in natural language in the different terms used to describe X and Z, LLMs don't have problems accepting two contradictory positions and will present longwinded and very plausible sounding arguments to reconcile the contradiction. (Perhaps neurosymbolic AI will address this contradiction issue but I don't know much about it.)
You might want to check out my recent close reading of Grokipedia: https://caad.info/analysis/newsletters/cop-look-listen-issue-09-20-nov-25/ -- though producing blandly right information most of the time, its still working in manipulation fairly regularly across entries